LLM-Stream
This UI pattern was a major inspiration for building SpeedyBot 2.0-- how to efficiently allocate the edits to "stream in" responses from an LLM service.
You can make up to 10 edits on a WebEx message which can approximate the "stream-in" effect on some LLM applications (otherwise the latency involved with forcing a user to "just wait-it-out" until the model completes is an awful experience)
Streaming is implemented using: https://github.com/axflow/axflow (from https://axflow.dev), although vercel and others have libraries that could work
Example Stream:
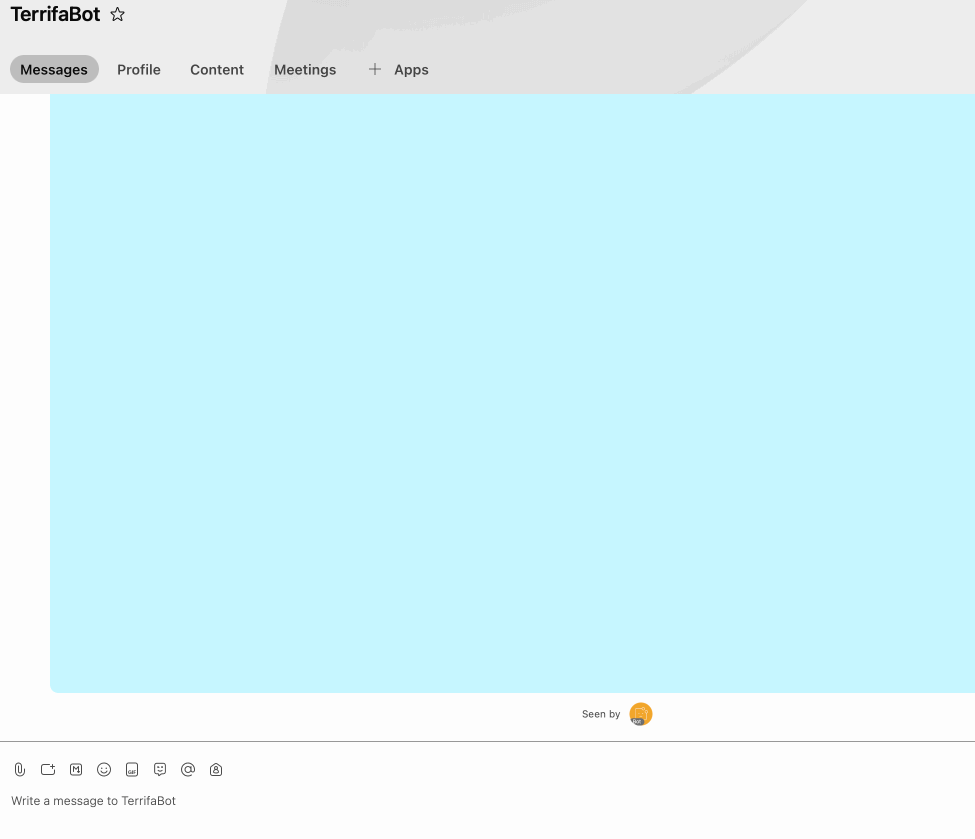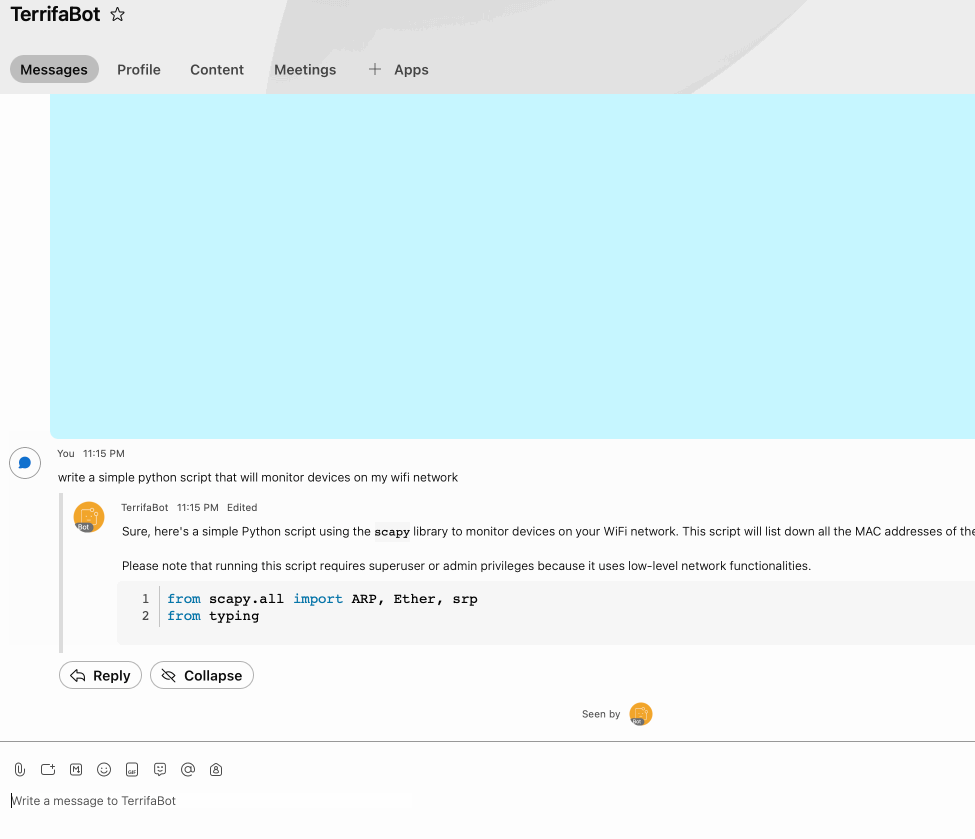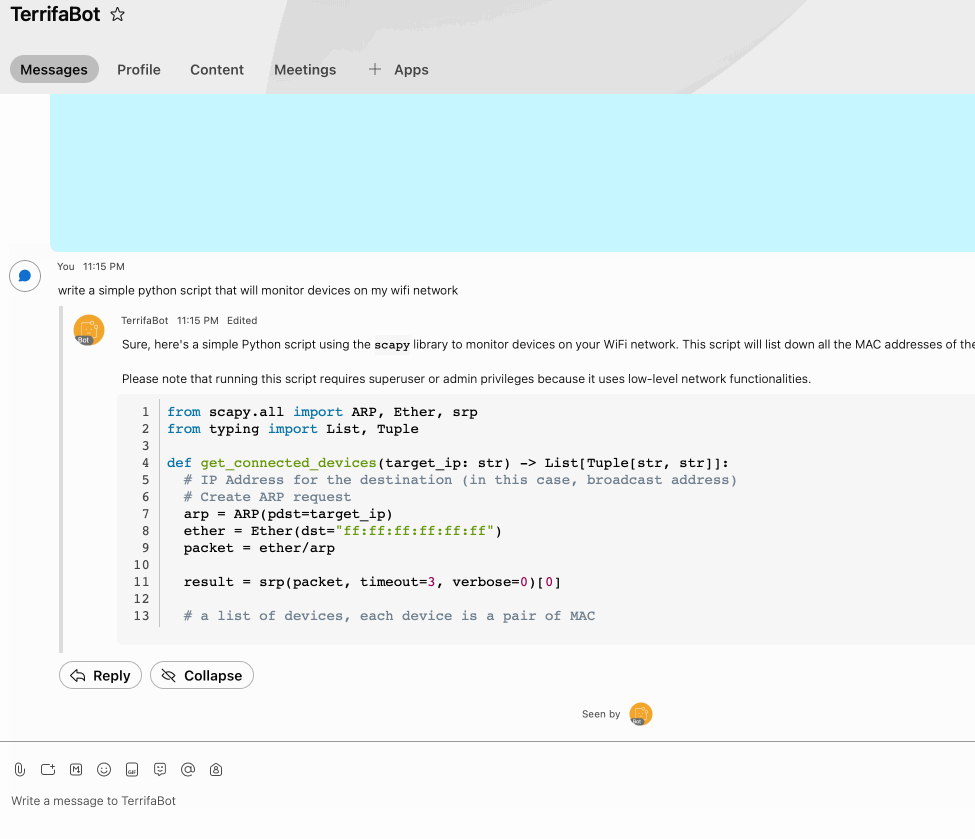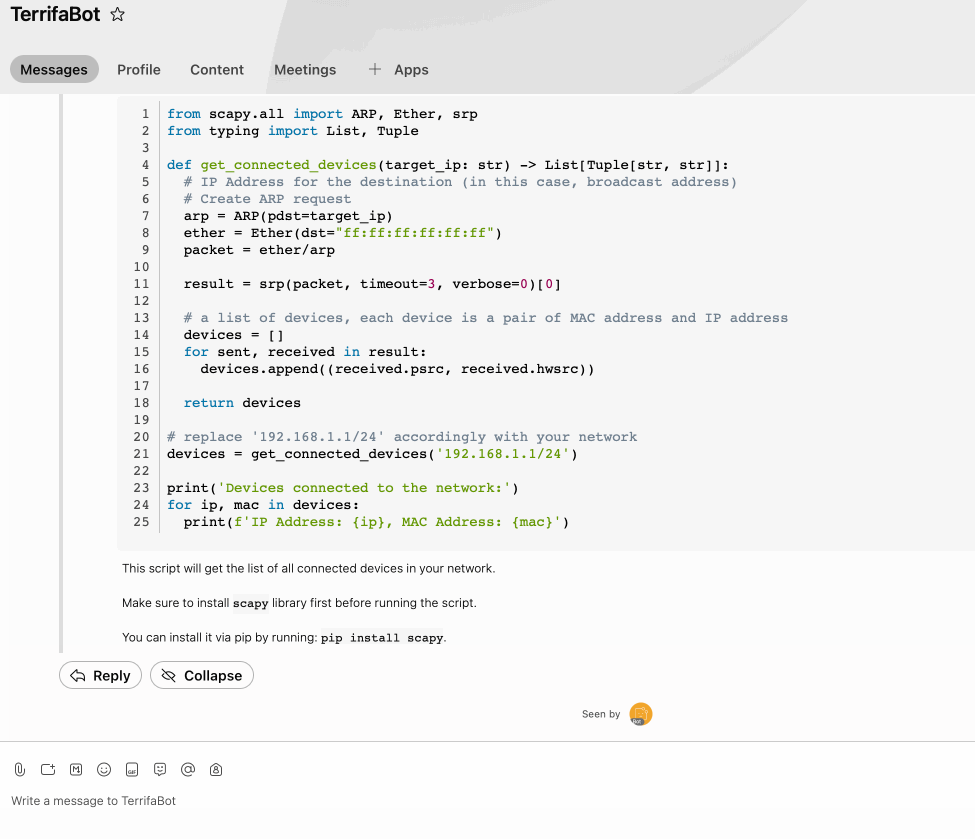
1) Fetch repo & install deps
git clone https://github.com/valgaze/speedybot
cd speedybot/examples/worker
npm i2) Get + Set your bot access token
Create a bot from scratch here + copy the token: https://developer.webex.com/my-apps/new/bot
If you have an existing bot, get its token here (regenerate a new token): https://developer.webex.com/my-apps
You can set your BOT_TOKEN by running this script in the project directory:
npm run bot:setup <your_token_here>
Set token by hand
Copy the file .env.example as .env in the root of your project and save your access token under the BOT_TOKEN field, ex
BOT_TOKEN=__REPLACE__ME__3) Set your OpenAI api Key
- Grab an OpenAI API key from here: https://platform.openai.com/api-keys
Add it to your .env file manually or by running the following command:
npm run bot:addsecret OPEN_AI_KEY=sk-abcdefhg73624429defghijkl5Your .env file should look like this:
OPEN_AI_KEY=__REPLACE__ME__
BOT_TOKEN=__REPLACE__ME__4) Take it for a spin
Send a message to your agent and attempt a generation
- This is a bare-bones example which can be easily extended-- To see a reference (which depends a storage/state mechanism) which will manage conversational context + swap personas, handle file-uploads (.doc, xlsx files, and other) and inject into prompt, see here: https://github.com/valgaze/speedybot-gpt4
Note: this example happens to use OpenAI, but you can swap-in HuggingFace, Anthropic or roll your own